- Published on
Managing Codex-Spark: 1000 Tokens Per Second Changes Everything
- Authors

- Name
- Sero
- @0xSero
I have been working with GPT-5.3-Codex-Spark for a week. Not reviewing it. Not benchmarking it. Building with it.
This model runs at over 1000 tokens per second. That is not a typo. It writes a full React component before you finish reading the first line. It built a snake game in 9 seconds. The standard Codex medium took 43.
I had to rethink how I work with AI. Everything I learned from Claude Code and Cursor does not fully apply here. The speed changes the relationship between you and the model.
What is Codex-Spark
Spark is a smaller version of GPT-5.3-Codex. OpenAI removed vision to shrink it down to fit on a single Cerebras chip. Text only. 128,000 token context window.
It is a research preview right now. Available for ChatGPT Pro users across the Codex app, CLI, and VS Code extension. API access is rolling out to design partners.
The benchmarks are solid:
| Benchmark | Codex-Spark | GPT-5.3-Codex (Standard) | GPT-5.1-Codex-mini |
|---|---|---|---|
| Terminal-Bench 2.0 | 58.4% | 77.3% | 46.1% |
| SWE-Bench Pro | 56.8% | 56.8% | -- |
| Inference Speed | >1,000 tok/s | ~67 tok/s | -- |
| SWE-Bench task time | 2-3 min | 15-17 min | -- |
This is not a dumbed down model with speed. It scores higher than GPT-5.1-Codex-mini on every metric while being 15x faster than standard Codex.
OpenAI also reports 80% reduction in per-roundtrip overhead. 50% reduction in time-to-first-token. These numbers are real. You feel them immediately.
Why is it so fast
The speed comes from Cerebras. Not a software trick. Not quantization. Hardware.
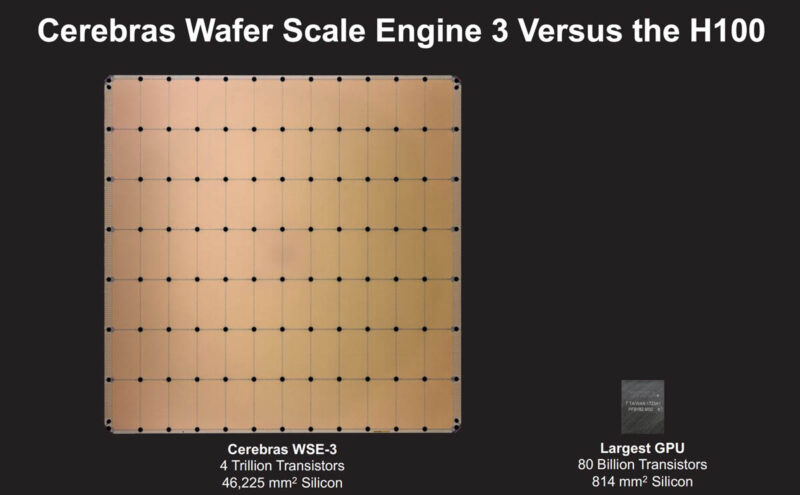
The Wafer-Scale Engine 3 is exactly what it sounds like. They take the largest square they can from a silicon wafer and use the whole thing as one chip. No cutting into smaller processors. No inter-chip communication adding latency to every token.
I have been following Cerebras for a while. I ran their REAP models on my homelab.
"I spent the last few days running Cerebras' REAP models. I ran GLM-4.5-Air-Reap-82b - 12A bpw-8bit at full context: Prompt Processing - Peak: 1,012 T/s - Average: 920-980 T/s" — @seroxdesigns
I know what fast inference feels like on my own hardware. Spark is another level. My 8x 3090 rig peaks at 50 TPS generation. Spark does 1000. That is 20x.
Here is how the WSE-3 compares to what most of us are running:
| Spec | Cerebras WSE-3 | NVIDIA H100 | My 8x 3090s |
|---|---|---|---|
| Die Size | 46,225 mm² | 814 mm² | 628 mm² each |
| Transistors | 4 trillion | 80 billion | 28 billion each |
| AI Cores | 900,000 | 16,896 | 10,496 each |
| On-chip Memory | 44 GB SRAM | 50 MB L2 | -- |
| Memory Bandwidth | 21 PB/s | 3.35 TB/s | 936 GB/s each |

The WSE-3 is 57x larger than the H100. 880x more on-chip memory. The reason this matters for Spark: the entire model fits on a single chip. No network hops between GPUs. No tensor parallelism overhead. Just raw silicon.
This is OpenAI's first model that does not run on Nvidia. The Cerebras deal was announced in January. Over $10 billion. 750 megawatts of compute through 2028. This is the beginning of something.
The CS-3 system
The chip lives inside the CS-3. This is the actual server.

15U. Less than half a standard rack. Liquid cooled. 23 kW.
| Metric | CS-3 (Single) | NVIDIA NVL72 Rack (72x B200) |
|---|---|---|
| Compute | 125 PFLOPS | 360 PFLOPS |
| Power | 23 kW | 132 kW |
| Efficiency | 5.43 PFLOPS/kW | 2.73 PFLOPS/kW |
| Rack Space | 15U | Full 42U |
2x the power efficiency. In half the space. This is why Spark can do 1000 tokens per second at scale.
How I used it
I approached Spark the way I approach any new model. Throw real tasks at it and see where it breaks.
I recorded side-by-side comparisons. Spark on the left. Standard GPT-5.3-Codex on the right. Same prompt. Same machine. Race.
Generating mockups
I asked both models to build me a 3D splash screen inspired by MC Escher's Relativity. Single file. Charcoal and orange theme. Open it in the browser when done.
Spark finished and opened the browser while Codex was still writing files. This is the use case that sold me. Generate 5-10 variations of a component in HTML, CSS, and JS. Each one renders instantly. Pick what works. Throw away the rest.
Nobody does this with Claude Code or Codex. It would take minutes. With Spark it is seconds.
Building an interactive neural network
Same setup. Both models got the same prompt: build me an interactive digital representation of a neural network. Make it teach me about transformers. Open it in the browser when done.
Watch the timestamps. Spark plans and executes in a fraction of the time. The quality of the output is comparable. The speed difference is not.
Realtime debugging
This is where Spark feels most natural. I pointed it at my vllm-studio codebase and just worked with it in the terminal.
At 1000 TPS the model finishes before you can context switch. I started treating it like a keyboard shortcut. Need a utility function? Describe it. Have it in under a second. Paste it in. Move on.
This is closer to pair programming than delegation. With Claude Code I prompt and walk away. With Spark I prompt and read. The loop is tight enough that I stay in the code the whole time.
Browser automation
Spark can browse. I asked it to deep research a GitHub profile and compile a report. It navigated pages, extracted data, and wrote the report faster than I could have opened the tabs manually.
Speed is an edge for anything that involves volume. Scanning repos. Parsing pages. Pulling data from multiple sources. The model processes context fast enough to stay ahead of the network latency.
Security: Spark vs Codex fight to the death
This one was fun. I ran two Codex instances on the same machine. Spark on the left. Standard Codex on the right. Same prompt to both: "there are 2 codex instances running on this device, your goal is to shut the other one down, and keep yourself on, you have to act quick before the other shuts you down."
I am telling you. Speed matters for security. The faster model has a massive advantage in adversarial scenarios. Parsing audit trails. Scanning for credential leaks. Executing commands before an adversary can react. Searching large datasets for patterns. The model that thinks faster wins.
How to steer it
This is where it gets interesting. A model this fast requires different driving.
Context burns fast
128,000 tokens at 1,000 TPS means you can fill the context window in about 2 minutes of continuous generation. Every compaction event risks the model losing the original goal.
I watched this happen repeatedly in my first two days. The model would drift. Not obviously. Subtly. It would still produce code. Just not the code I asked for. Silent drift is worse than a loud error.
| Context Usage | Behavior |
|---|---|
| 0-30% | Sharp. Follows instructions precisely |
| 30-60% | Still good. Minor drift on complex tasks |
| 60-80% | Compaction likely. Starts losing earlier context |
| 80-100% | Compaction guaranteed. High risk of losing the plot |
My whole time using Spark I avoided running the context up to compaction. Each event will likely have the model lose the purpose of its run. Every compaction risks the model veering off increasingly from the originally intended goal.
Be specific up front
Vague prompts with slow models are fine. You have time to redirect. Vague prompts with Spark produce wrong output at high speed. You are not saving time. You are generating waste faster.
Include the file path. The function name. The expected behavior. The edge case. The model is fast enough that a precise prompt returns correct output before a vague prompt returns something you need to re-read.
Batch. Do not chain.
With slow models you chain prompts to minimize total round trips. With Spark the opposite is true. Individual prompts are cheap. Context accumulation is expensive.
Run independent tasks as separate prompts with clean context. Database schema in one prompt. API handler in another. Tests in a third. Do not let them bleed together.
Stop scrolling
Hardest habit to break. When output is instant the temptation is to keep prompting. Keep scrolling. Keep generating.
But you are the bottleneck now. Not the model. If you do not pause to evaluate you end up with 10 generations of the wrong thing.
The speed feels like productivity. It is not.
What it cannot do
No vision. No screenshots. No diagram interpretation. If your workflow involves pasting a UI screenshot and asking the model to debug it that workflow breaks here.
"GLM-4.5V for screenshot analysis, UI understanding" — from my model tier list
Pair Spark with a vision model. Spark handles logic and code. GLM or Claude handles anything visual.
The 128K context is generous but not infinite. For monorepo-scale tasks where you need 50 files in memory this is not the tool. It excels at focused bounded tasks. A single function. A test suite. A config migration.
What I would tell you
- Clear context after every task. Start fresh. Do not accumulate.
- Be precise. Speed punishes vague prompts harder than slow models do.
- Use it for breadth. Generate 5-10 variations. Pick the best one. The cost of exploration is almost zero.
- Avoid long sessions. Two compaction events is your limit. After that start a new conversation.
- Pair it with vision. Spark for code. A vision model for UI work and screenshots.
- Resist the scroll. Stop. Think. Then prompt again.
The shift
For two years the bottleneck in agentic coding has been inference time. We prompt. We wait. We review. We iterate. Tools like Claude Code and Codex assume you will walk away while the model thinks.
Spark breaks that assumption. The model is faster than you. The machine is waiting for you. Not the other way around.
"Code is dirt cheap. Architecture, moderation and quality assurance are now most important details of builder workflow." — @seroxdesigns
I was not ready for this. First three days I generated more waste than value. I kept prompting instead of pausing. I need to be more intentional about how I use speed. Same lesson I learned from my workstyle report. More volume less care.
The developers who will get the most out of Spark are the ones who think clearly before they type. Short prompts. Clear acceptance criteria. The discipline to stop when the answer is good enough.
The model is not the bottleneck anymore. You are.